Research Projects
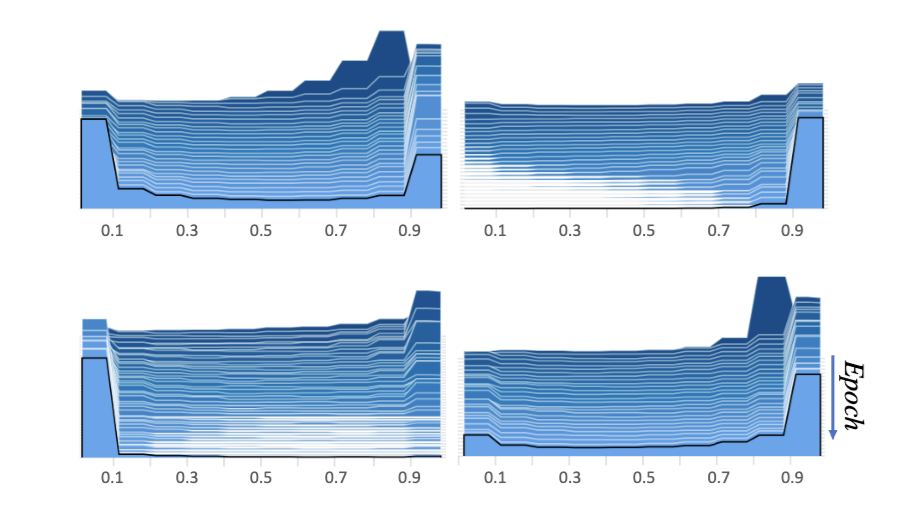
Dirichlet-Prior Shaping
Published @ICML'26
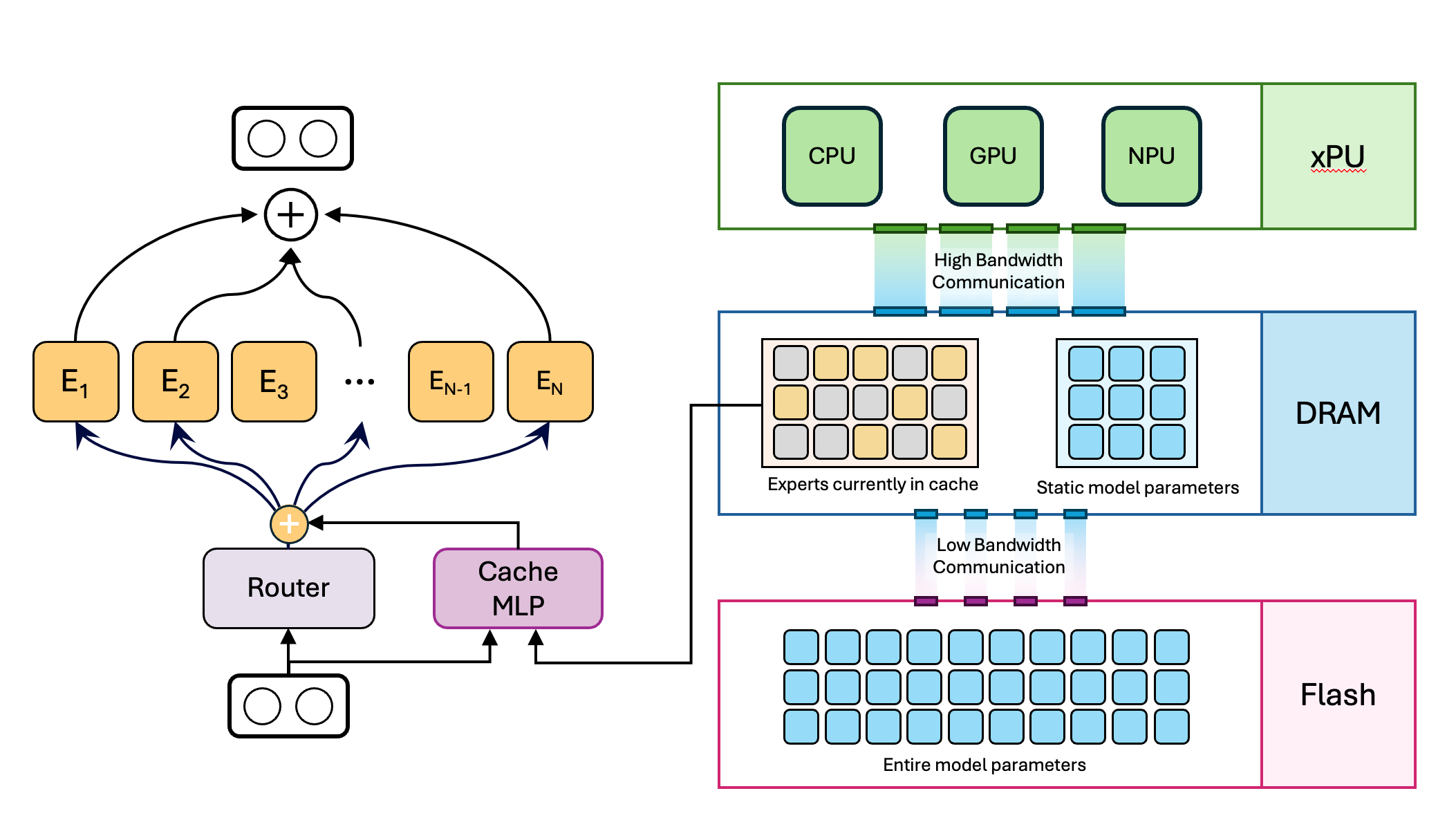
Guiding expert specialization in MoEs via Dirichlet-Prior Shaping (DPSL). DPSL is a powerful tool to instill a wide array of desired statistical properties into the router's behavior.
MoE
Dirichlet-Prior Shaping
Upcycling
Expert Specialization
Batch-shaping Loss
LLM Efficiency
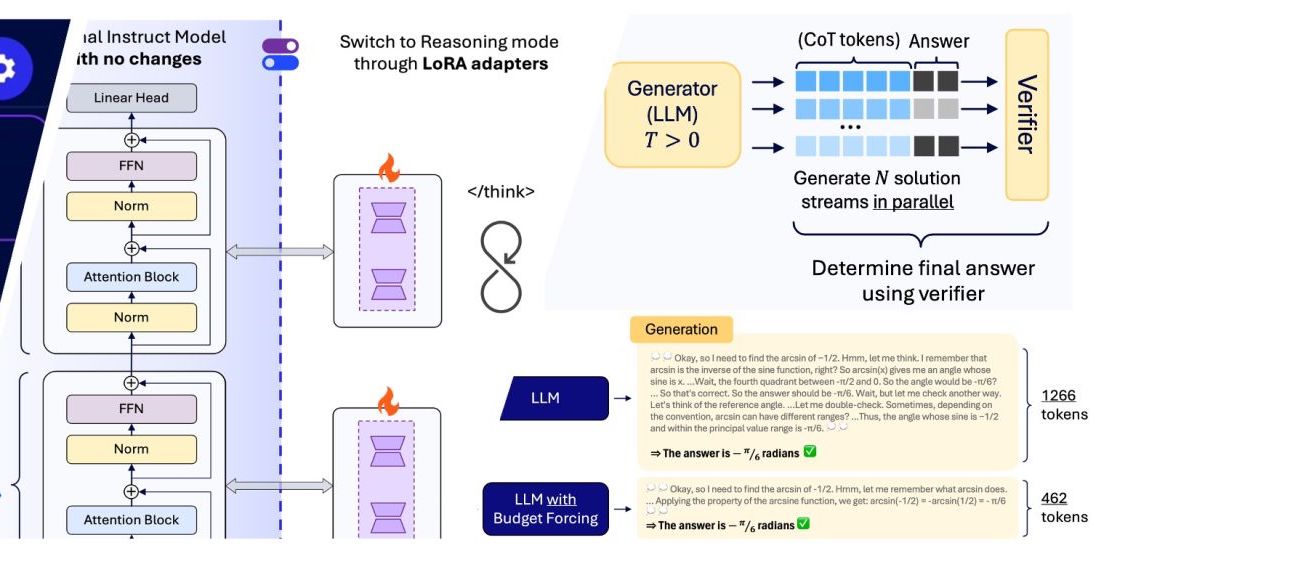
Reasoning on the Edge
Qualcomm AI Research | Tech Report'26
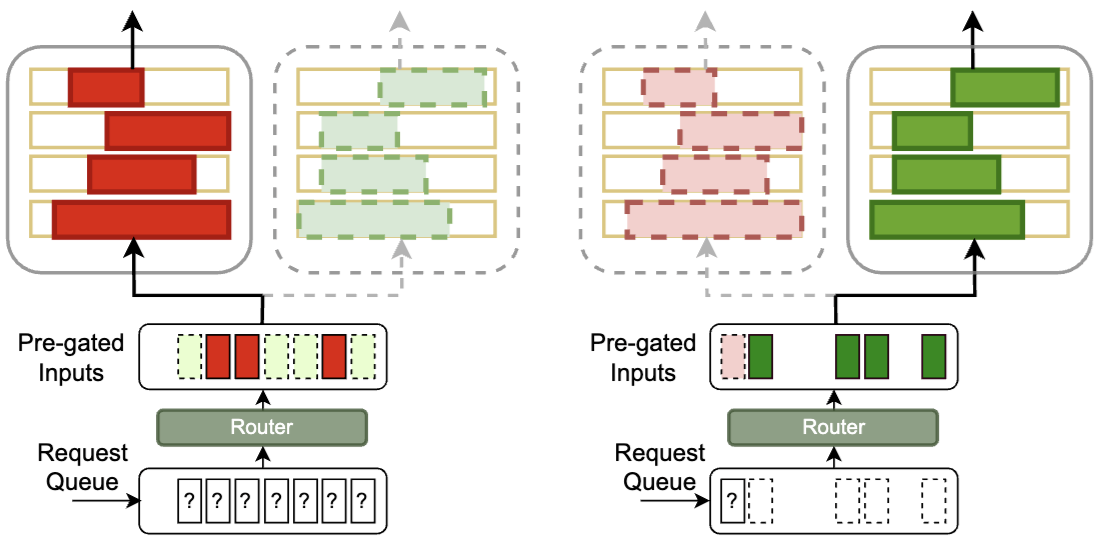
Reasoning in small LLMs using LoRA adapters, combined with supervised fine-tuning and RL-based Budget forcing.
LoRA
RL for budget forcing
Chain-of-thought
Model switching
Reasoning
On-device
LLM Efficiency
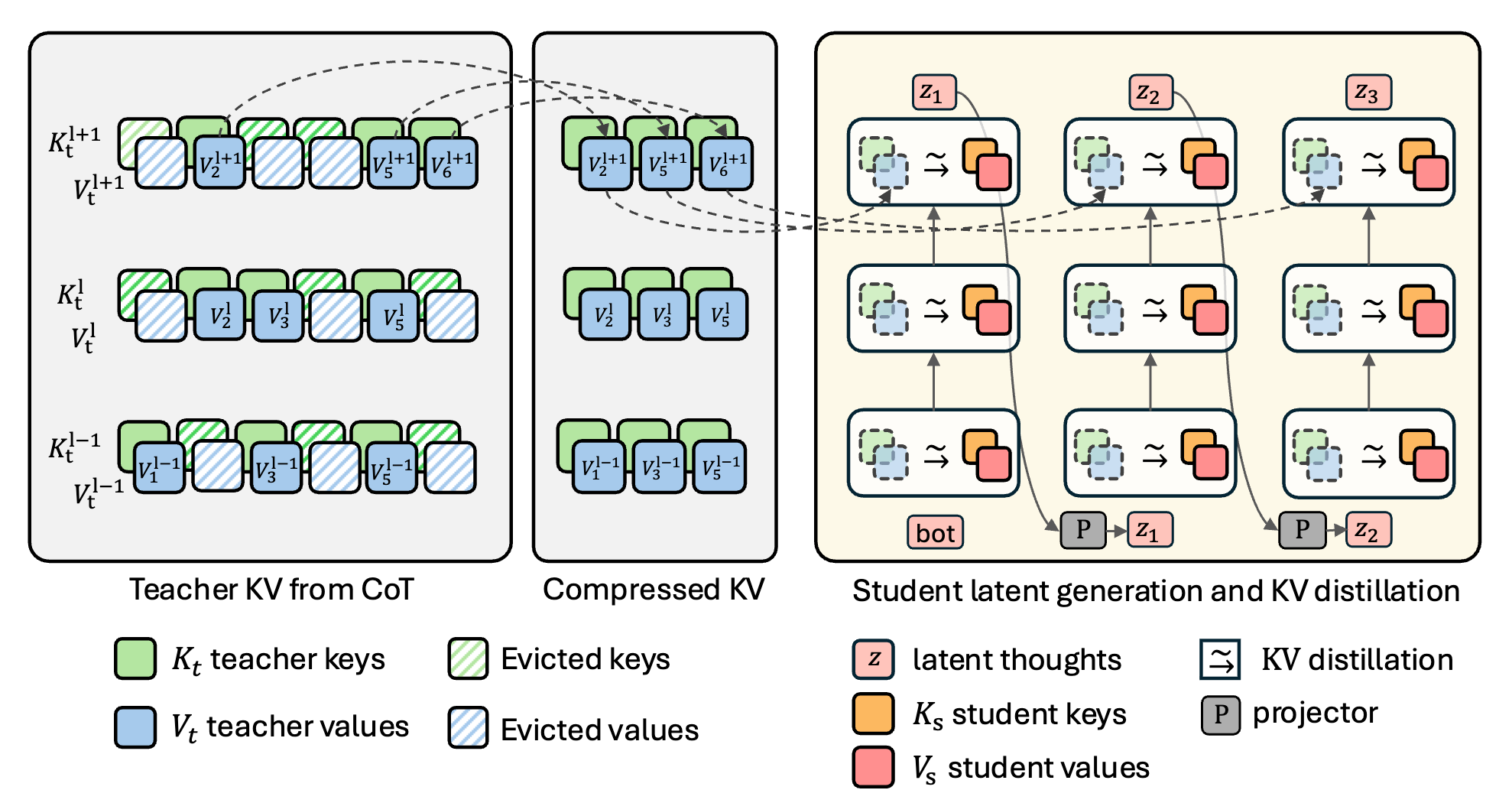
LATENT REASONING
Published @ICLR'26
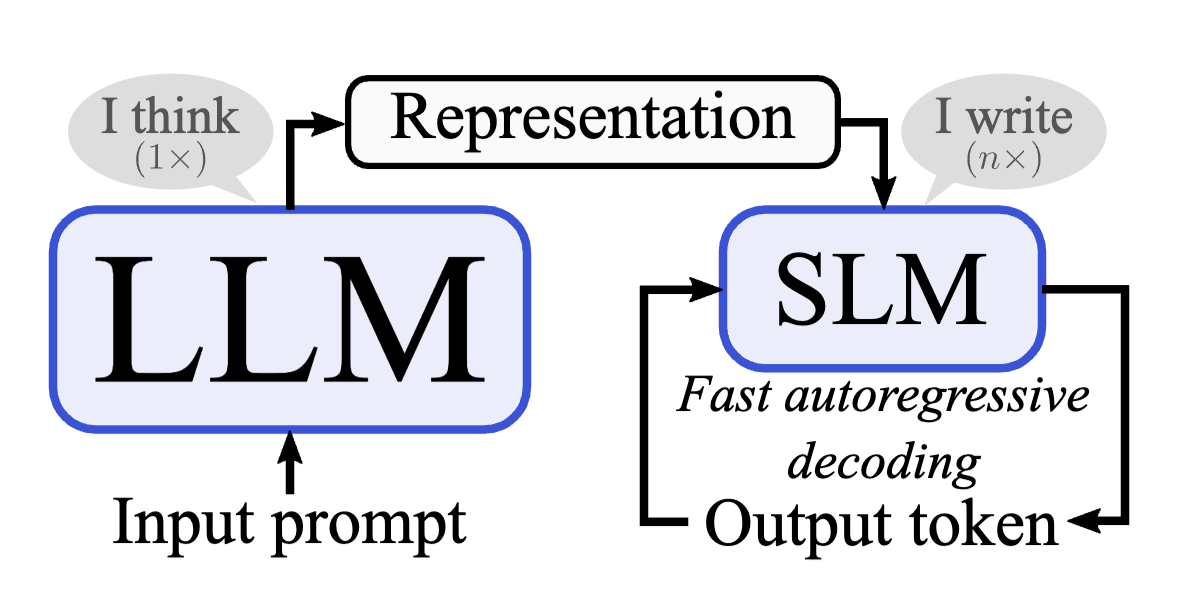
Distilling knowledge from a compressed KV-cache of a teacher into a latent-reasoning student.
Latent Reasoning
KV-cache
KV-cache distillation
Chain-of-thought
LLM Efficiency
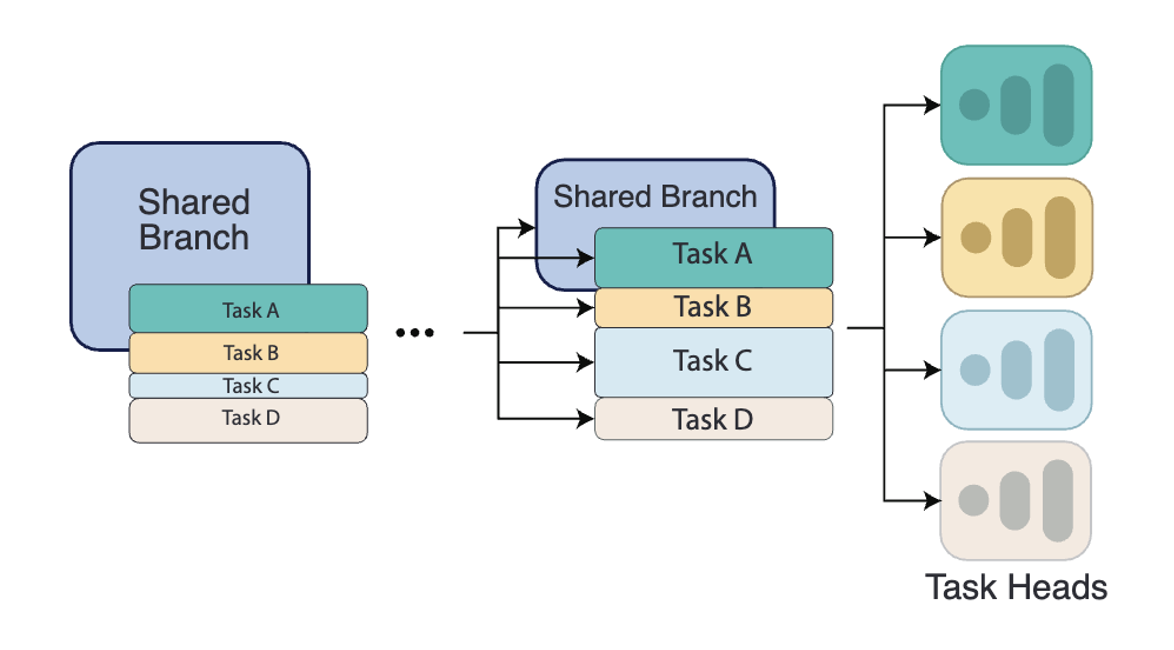
InterroGate for MTL
Published @BMVC'24
Learning to share, specialize, and prune representations for Multi-task Learning.
Multi-task Learning
Inference efficiency
Gated Networks
Channel sparsity
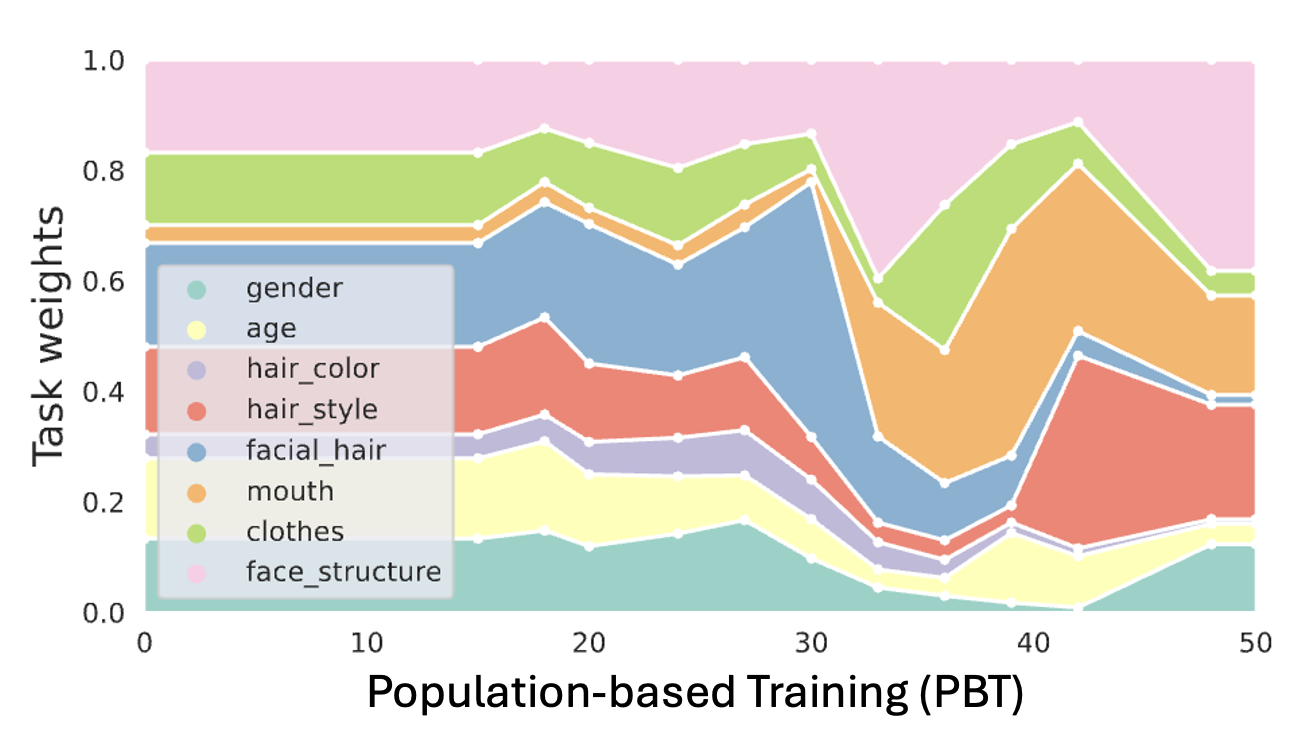
Scalarization for MTL
Published @NeurIPS'23
Scalarization for Multi-Task and Multi-Domain Learning at scale.
Population-based Training
Scalarization
Multi-Task Learning
Multi-Domain Learning
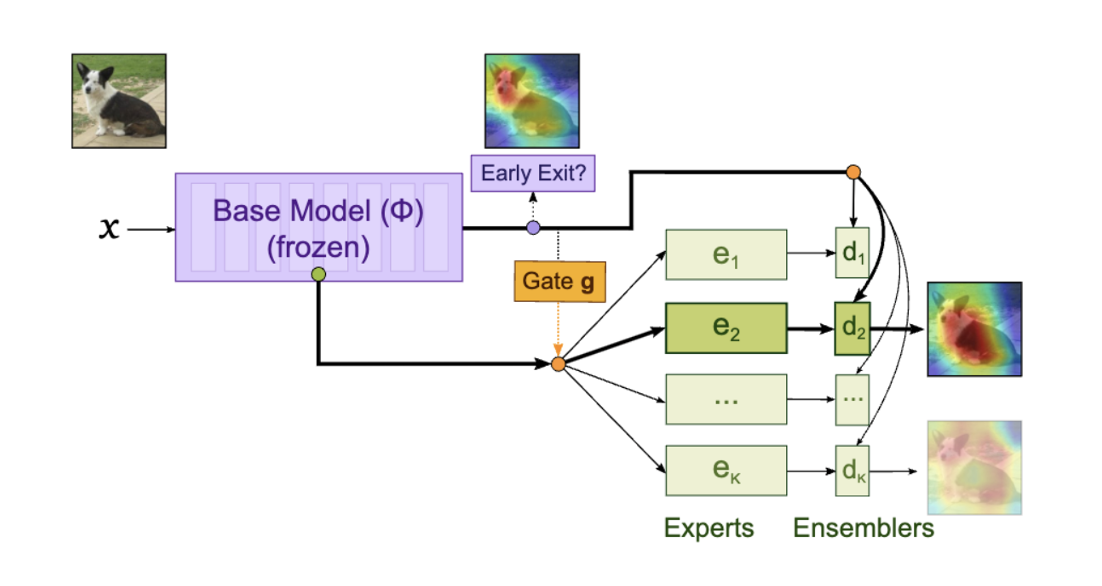
Single-gated MoE
Published @BMVC'22
Single-gate Mixture of Experts (MoE) with early exiting for convolutional architectures.
MoE
Anytime Inference
On-device
Early-exiting

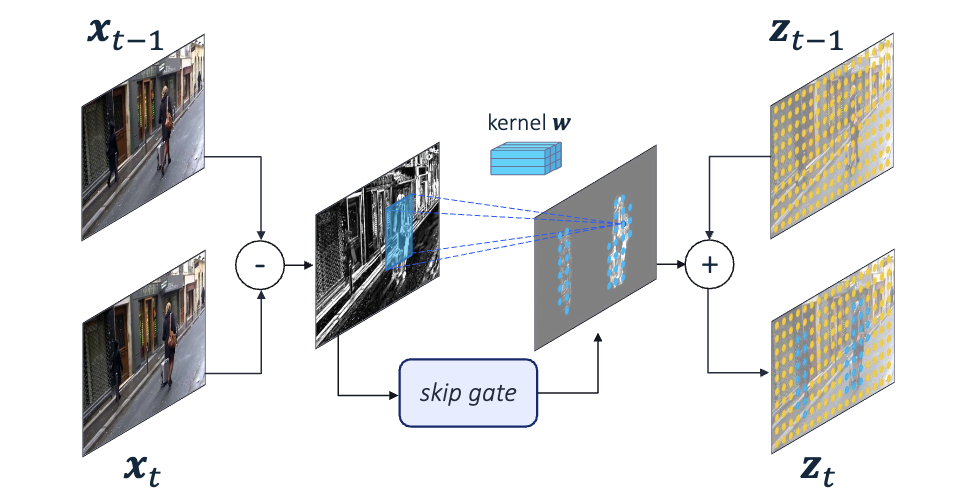
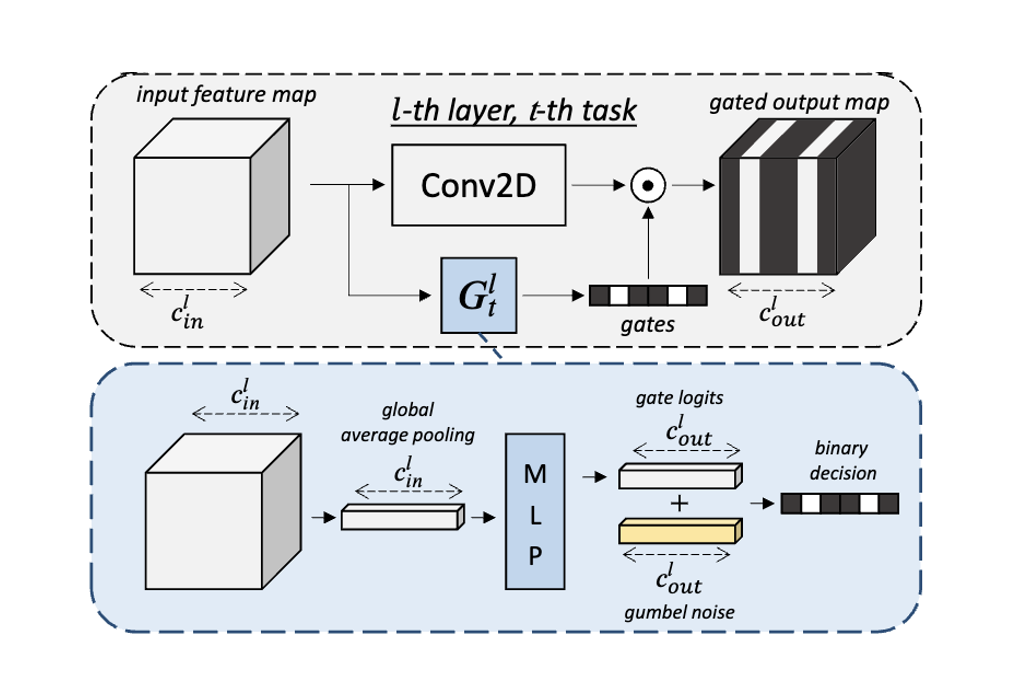
Channel Gating for Continual Learning
Published @CVPR'20 (Oral)
Conditional channel gated networks for task-aware continual learning.
Continual Learning
Chanel-Gating
Task-aware
Dynamic sparsity